
はじめに
※記事一覧
今の時代となっては残念ながらラブプラス画像が少ないので、無いなら自分で作ればいいやと最近AIイラストをはじめたんですが、最初の頃は初心者すぎて何を調べればいいのかも分からず困り果てたものです[A]画像は執筆者のイメージです。読もう、『ハトのお嫁さん』!。

インターネットやPCの知識はそこそこあるけど、AIイラストについては何もわからない。そんな人の導入ハードルが少しでも下がるようにと当記事を執筆しています。
記事全体の描写粒度についてですが、あまり詳しく書くと初心者には逆効果だと思うので、敢えて大雑把かつシンプルに書いていきます。概念がわかって慣れてきたら、自分で検索して他のサイトの記事などを見て知識を深めていくのがよいでしょう。
なお当記事のタイトルは『サルでも描けるマンガ教室』のもじりです。最初は相原と竹熊の会話形式で記事を書こうと思ったんですが、かなり大変なうえに30年近く前の作品ということもあり、意味分かる人は少数派だと判断したので普通に記事を書いていきます。
とりあえずサクッとラブプラスの画像を一枚生成したい、という目的であれば以下の3記事だけ読めばいいと思います。
・01:用語解説(当記事)
・02:環境整備
・03:画像生成
Stable Diffusionって何?
まず最初の鬼門ですが、Stable Diffusionとその構成要素の概念が直感的に分かりづらい、ってところかと思います。一度わかれば難しくないんですが、個人的に最初にここで臆してしまった感があるので、大雑把な説明をしてみます。
まずは下図を見てください。英語しか書いてないので抵抗あるかもしれませんが、一つずつ用語を解説していきます。
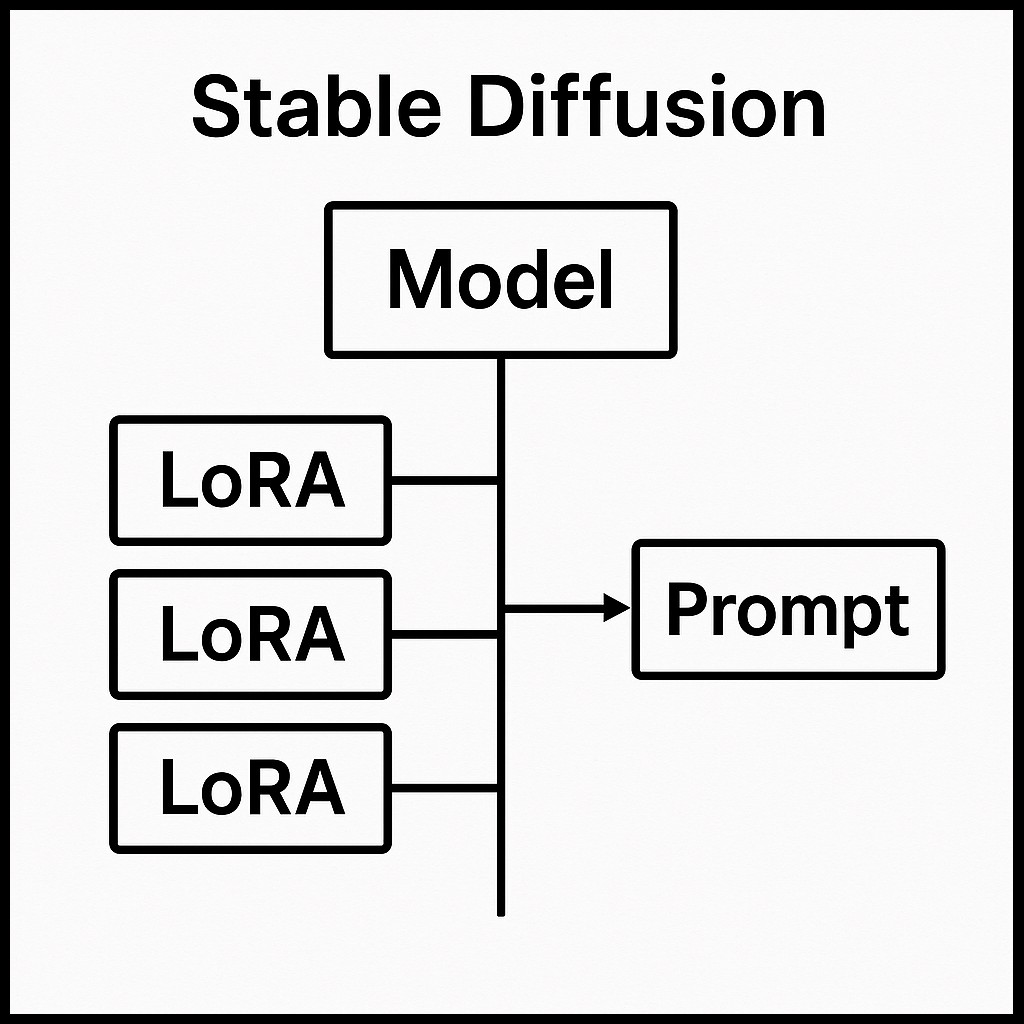
この図だと味気ないので、ナノバナナPRO先生に作ってもらったイメージ図がこちらです。

Stable Diffusion
ステーブルディフュージョン。AIイラストを書くための無料ソフト一式。
ニンテンドースイッチ本体みたいなもの。これだけあっても何もできない。後述するModelが必要。
Model(CheckPoint)
モデル(チェックポイントともいう)。AIイラストを書くための学習データ。だいたい数ギガくらいのファイル。
ニンテンドースイッチで言ったらゲームカセットみたいなもの。画風とかが左右されます。
適用できるモデルは1つのみ。
LoRA
キャラとか衣装といった個別学習をしてるファイル。
ニンテンドースイッチで言ったらDLCみたいなもの。
たとえば「寧々さんを描きたい!」と思ったら、寧々さんのキャラを学習させてるLoRAを探してきて適用すれば、楽に実現できるわけです。
LoRAは複数適用することができます。
Prompt
プロンプト。世間では呪文とも呼ばれる。英語で生成したい画像の内容を指示します。
ファミコンで言ったらコントローラーみたいなもの。ファミコンとカセットがあっても、コントローラーで指示をしないと操作はできません。
どういう風にプロンプトを書けば、自分が思った通りのAIイラストが生成されるのか、ここが永遠のテーマになるかと思います。
Negative Prompt
さっきの図に書いてないですが、Negative Prompt(ネガティブプロンプト)というものもあります。
さっきと逆で、出したくないものを指定します。
「清楚な寧々さん画像を出したいのに、なんどタイムリープしても乳首が出てきてしまう! なぜだ、俺がエロいからか?!」
というような時に「nipples(乳首)」と指定すると出にくくなります。
SDとSDXLについて
さっきの図には出てきてないですが、重要な要素なので触れておきます。
生成する画像の大きさによって、SD1.5とかSDXLといった分類ができます。SDXLの方が大きな画像に対応してて、きめ細やかな画像が出やすいものの、要求されるPCスペックは高くなります。とはいえ宗教上の理由とか特殊なことがないかぎり、今から始めるのならSDXLを使ったほうが余計な苦労をしないと思います。
いちばん知っててほしい点ですが、SD1.5とSDXLは互換性がありません。モデルやLORAなどはそれぞれの系統のものを使い分けましょう。
手軽な無料サイト
以上の簡単な概念が分かったら、いきなりゲーミングPCを買ったりせずに、無料サイトで実際に生成してみてはどうでしょうか。
個人的にオススメするのはPixAIです。
PixAI:AIイラスト·AI画像専用の投稿&生成サイト(無料)
NovelAIといった有料サービスもかなり利用者が多いのでいいかもしれませんが、今回は初めての生成という状況を考慮して、まずは無料サービスで触っていきましょう。PixAiでは毎日無料で1万クレジットもらえますので、それで数回は生成できると思います。
あまり難しい事考えずに、生成したいような画像を検索などで探してみると、割とプロンプトを公開してる画像が多いです。それを流用して生成する機能が備わってるのが、このサイトのウリの一つだと思います。実際に生成してみて、モデルやLoRAやプロンプトがどういうものか肌で感じてみましょう。
ためしているうちに「生成回数に制限があって物足りない、もっと色々やってみたい」と感じてきたら、PC購入も視野に入れてもいいかもしれないですね。
オススメの記事など
Stable Diffusion関連の記事を探す場合、少し昔の記事だと今となっては役に立たないって事も多いので要注意です。そういう意味で個人的なおすすめサイトを紹介していきます。
スタジオ真榊
月額千円かかりますがスタジオ真榊|pixivFANBOXを推奨します。有用な情報が大量にあり、古い情報については新しい記事へのリンクを用意して誘導したり、と情報が古くならないような工夫もあって素晴らしい。
まずは無料記事もあるので雰囲気を掴んで、その時の自分に必要だと思ったら課金してみてはいかがでしょうか。下記の導入用の解説無料記事、長いので腰が引けるかもしれませんが、内容としてはとても分かりやすいので、当記事で最小限の言葉の意味が分かったうえで読むと、より理解が正確に深くなるかと思います。
【2026年版】AIイラストが理解る!StableDiffusion超入門|賢木イオ
37番氏のNote
他にはアイマス画像系の巨匠こと37番氏のNoteには、コンパクトながらもツボを抑えた情報の掲載がされてます。超初心者だと最初は意味が分からないかも知れないけど、やってるうちに分かってきたり、ググってわかるようになったりすると思うので、インデックス的な感じと捉えて有益情報に触れてみてはいかがでしょうか。たまにTwitterでこのようにプロンプトの紹介されてるので、フォロー推奨しておきます。
showgirl skirtと相性が良いPrompt 2/2
混ぜやすいヤツ(全部指定しても言うことを聞く)
detached sleeves,lace trim,see-through, glitter,frills,embroidery,fluffy,ornament混ぜにくいヤツ(競合するので指定は以下からは1つのみに絞る)
iridescent clothes,sequins,ribbed,latex pic.twitter.com/U0lRHNxKjg— 37bann2 (@37bann2) April 12, 2025
おわりに
今回は概念的な話をしました。基本的な用語のイメージはついたでしょうか。
ここがわからないままWebを調べてもちんぷんかんぷんだと思うので、必要経費と思ってまずは用語をふんわりとでもいいので意味を理解しておいてください。
コメント