
はじめに
※記事一覧
「DOAXVVのドスケベ水着をラブプラスのカノジョにも着せてみたい」と思ったことはないですか?
LoRAがあれば、それができちゃうんです。
とはいえLoRA作成は結構最初は敷居が高かったです。ローカル環境でLoRAを自作する方法があるのは知ってるんですが、下記の記事ほどに懇親丁寧に説明されてても「パラメータ多そう……意味わからん……」って敬遠してました。

【Stable Diffusion】StabilityMatrixでSDXL版LoRAを作ってみるまで【Kohya_ss】|カズヤ弟@ゲーム実況&生成AI
そこで自己流での作成方法をお伝えします。必要なのはPixAIでのクレジット貯め、画像集め(DOAXVV水着)くらいです。
PixAIでクレジットを貯める
無料アカウントでも、日々のタスクや申請でクレジット(生成などに使うサイト内通貨)を貯めることができます。
たとえば画像16枚でSDXL学習をすると25,000クレジットほどかかるので、地道にクレジットを貯めていきましょう。
無料クレジット貯めのタスクについては以下になります。
・1日01回、10,000クレジット申請
・1日10回、生成画像の投稿(1,000*10クレジット)
・1日03回、投稿時にTwitterなどで連携(1,000*3クレジット)
・1日01回、スマホアプリで広告を見る(5,000クレジット)
合計すると1日に28,000クレジットを入手できることになります。
とはいえ生成画像を作る必要があるので、その分のクレジットは事前に必要となります。
SDXLモデルだと4枚生成で約3,000クレジットかかりますが、SD1.5モデルだと約1,000クレジットくらいですみます。よって約1,000クレジット*3回で画像生成していけば、クレジットを貯めやすいと思います。
画像を用意する
DOAXVV内での撮影機能を使い、学習用の画像を撮影します。
画像サイズが小さすぎると学習に向きませんが、SDXLの場合は1024*1024の画像が望ましいです。逆に言うとこれ以上大きくても意味がないです。よってDOAXVV起動時の画面サイズはフルHD(1920*1080)にして撮影しましょう。
余計な背景が無い方が学習的に好都合なので、スタジオ(黒)にて撮影しましょう。DOAX3の水着撮影だとスタジオ(黒)がないので、スタジオ(桃)で撮影してから、EagleのAI自動背景除去などをつかって余分な背景が学習データに入りこまないように加工すればいいでしょう。
画像枚数はいろいろ諸説ありますが、自分はいろいろな角度で最低16枚撮ることにしてます。
参考までに自分の撮影ルーチンを紹介しておきます。
下記ポーズ名をテキストファイルなどに保存しておいて、VVでのポーズ選択画面上部にある検索窓にコピペするとスムーズですね。
びっくり
・正面・左右・上下(5枚くらい)
・背面・左右・上下(5枚くらい)※90度回転ボタンを2回押して背面を撮影わんわん ほおづえ
・おしりを撮影(1~2枚)暑いですね
片足を前に出す
・それぞれ左右入れ替えボタンを使って2枚ずつ撮影開脚斜め前屈
・大股開きを1枚仰向け 伸び
・仰向けに胸、股間を2~3枚
画像をトリミングする
DOAXVVで撮影した画像は、そのままだと1920*1080なので、1024*1024にトリミングしましょう。
アプリは色々あると思いますが、自分はRalphaを使ってます。
「Ralpha」複数のJPEG/BMP/PNG画像を高品位かつ高速に一括で拡大・縮小 – 窓の杜
下図のようにトリミング設定を用意して、後日も使えるようにiniファイル出力しておけば便利かと思います。
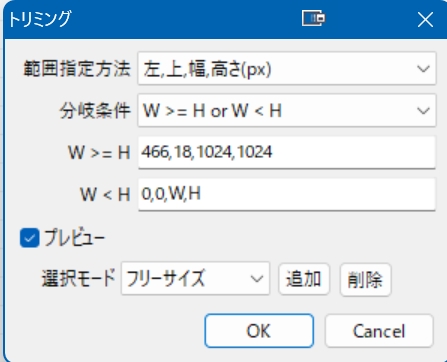
あとは一覧に画像をドラッグして、実行ボタンを押すだけで、配下に「resize」フォルダが作られてトリミング画像が出力されます。
画像から顔は消す
顔がはいると画風に影響が出やすいので、こんな風に顔だけ切り取るのも手段の一つです。
最初から顔が入らないように撮影するのも手ですが、あまりにも顔が入ってなさすぎると、顔が入ってないという事を学習しかねないので、顔は画像内に入れて手動で切り取ったほうが安定するかもしれませんね。
ポニーテールとかが残っていると間違って学習してしまうかもしれないので、髪の部分も消したほうがいいかもしれません。

PixAIでLoRA生成
PixAIの左上のロゴをクリックし、モデルをクリック
画面中央あたりにある「LoRA学習する」をクリック
画像をアップロードして、LoRAの名前をつけて、モデルを選択(もしラブプラスLoRA使ってるならillstriousなどがいいでしょう)、トリガーワードを設定します。
トリガーワードについては、適当にまずはLoRAの名前でもつけておけばいいです(あとからトリガーワード変更できるので)。
学習はすぐには始まらないので、のんびり待ちましょう。
学習が終わったらPixAIのお知らせ機能(システム欄)に連絡がきます。PCの場合、デスクトップ通知を有効にしてると終わったのがすぐわかるので便利です(iPhoneアプリで通知でもいいかと思います)。
一度に一回ずつしかLoRA作成はできないので、複数LoRAを作る場合は一つ終わってから次を、みたいな流れになります。
PixAIからローカル環境に適用
PixAIから自作LoRAをダウンロードして、ローカル環境のStable Diffusionに導入してください。
その際にトリガーワードや画像を自分で設定してください。トリガーワードが多すぎると、服装の一箇所だけ出したくないみたいな時に困りそうなので、トリガーワードは少なめにして、実質的に生成時に必要なプロンプトを説明欄に書いて取捨選択してもらう、みたいな手法がいいかもしれません。LoRAの正式公開する前にプロンプトを決めてしまえばいいと思います。
プロンプトで悩む場合は画像からタグ抽出(Tagger)して、Danbooruタグを設定しましょう。それでもダメな場合はChatGPTに質問してみてはどうでしょうか。プロンプトが効果的であるか試す場合は、一時的にHires. fixやADetailerのチェックボックスを外して、生成速度を早くしておくのがいいでしょう。
これは!という画像が出たらその時のSeed値を設定して、Hires. fixやADetailerのチェックボックスを戻して生成すれば高解像度で破綻がないほぼ同じ内容の画像が作れます。
こういった流れでプロンプトが確定したら、LoRAへトリガーワードを記載すればOKです。トリガーワードが多数あると、この要素は要らないといった時に困るかもしれないので、トリガーワードは一つにして、補填用のプロンプトは別に記載してあげる(LoRAアップロード先の説明に書くなど)、みたいにしておいた方が、人によって多様な使い方ができるかと思います。
LoRA使用時の注意点
・トリガーワード確認
→LoRA学習時のtrigger wordをプロンプトに絶対入れる
プロンプトの簡素化
→形状補足だけを書く。複雑な文にしない。
→やりすぎない、細かく命令しすぎないのがコツ(必要に応じて “simple background” で背景を静かにする)
LoRAの強度調整
→0.8〜1.2くらいで適正値を探る。衣装系といった複雑な内容だと1.0にしたほうが再現度が高くなる傾向があります。
トリガーワードがプロンプトに書いてないと、ほぼLoRAの内容は出てこないので、適切に形状のトリガーワードを設定して、プロンプトにも同じものを書きましょう。
足りてない部分があったら随時プロンプトに足してみて試し、有用ならトリガーワードにも反映、といったやり方もいいでしょう。
トリガーワードが適切だと確認できたら、PixAIの方のトリガーワード・必要プロンプトを修正してあげると親切でしょう。
DOAXVV水着LoRA
最近はおもにDOAXVVのドスケベ水着をLoRA化してます。

ダウンロード自由にしてますので、ローカル環境への適用も大丈夫です。というか自分のローカル環境で使いたいので、PixAIで作成しました。
商用利用もOKにしてます(もしかしたら設定ミスってるのがあるかもしれませんが、指摘いただければ商用OKに設定修正します)。
そのうちcivitAiにもアップロードしていくかもしれませんが、すでにgen558さんがかなり多数素晴らしいDOAXVVのLoRAをアップされてるので、自分の出番はないかなと思ってる次第です。
おわりに
自分はまだ試したことがないんですが、civitAIの方がLoRAの品質が良いらしいと聞いたことがあります。
civitAIだと実質的に有料でないとLoRA作成できないので試してませんが、そのうち機会があれば試してみるかもしれません。
今のところは手軽にPixAIでLoRA作っていこうかと思います。
コメント