概要
世の中には、ゲームのスクリーンショットをゲームごとに千〜万枚単位で保存して、それらの画像内のセリフで全てリネームして管理してる、というスクショ仙人が存在してるそうです。す、すげぇ……
真面目に言うと、各種スクショをゲーム別にフォルダ分けし、有用そうなスクショは書いてある台詞をファイル名に記載、返信するときに使いたい言葉でフォルダ検索すると使えそうなのが複数引っかかるのですぐに出せる仕組みです pic.twitter.com/C4Tdv67XUj
— Nore139 (@Nore139) 2017年12月9日
ここまでするとは、もはや修行……
呆然としつつも、この作業が少しでも楽にならないかな……と思って、C#2017でOCRツールを作ってみました。
PS4 :1920×1080
Switch:1280x 720
vita : 960x 544
3DS : 400x 240
上記のサイズの画像をいれた指定フォルダのjpg,png,bmp画像を読み込み、プレビュー表示させ、OCRでそれなりの精度で文字列を読取り、手動である程度修正してからファイルをリネームする、といったツールになります。
導入方法
OCRの部分は tesseract のDLLを呼び出す形になります。
上記を使うには Nuget でインストールする必要があるので、Visual Studio の最新版(現在は2017)の無償版をダウンロードしました。インストールが終わって、ツール用のソリューションを作ったら(今回はImageOcrRenameという名前にしました)、Nugetを使ってOCRを使えるように設定しましょう。
Visual Studio 2017
>ツール
>Nugetパッケージマネージャー
>ソリューションのNugetパッケージの管理
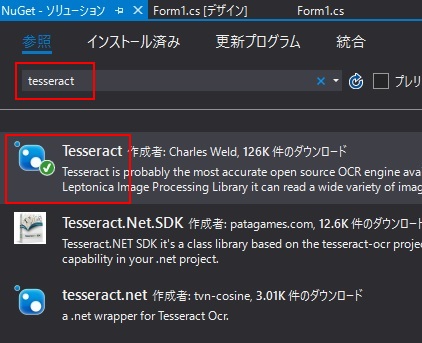
・左上の検索ボックスにて「tesseract」で検索
・Tesseract(v3.0.2)をクリック
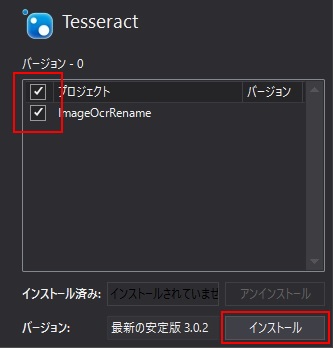
・右側の対象ソリューションをチェックし、インストールボタンを押す
もしパッケージマネージャーコンソールからコマンドでインストールしたい場合は、
Visual Studio 2017
>ツール
>Nugetパッケージマネージャー
>パッケージマネージャーコンソール
とすると画面下部あたりにコンソールが出てくるので、
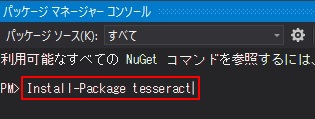
PM> Install-Package tesseract
と入力してENTERキーを押下すれば、自動的にTesseract 3.0.2がインストールされるかと思います。候補が複数ありますが、このページではTesseract 3.0.2の解説を行いますのでご注意を(それぞれでコーディングの方法やusing指定が変わってきます)。
○ Tesseract(v3.0.2)
× Tesseract.Net.SDK(v1.9.2)
× Tesseract-OCR(v1.0.4)
他の方法だと(特にTesseract.Net.SDK)、日本語の検出率が下がったり、画像によっては下記エラーが出たりしました。
Patagames.Ocr.Exceptions.NoLicenseException: ‘The requested operation cannot be completed due to a license restrictions. With the trial version the images which width is smaller than 500 pixels can be loaded without any restrictions. For other images the allowed widths is 500 – 550 pixels; 600 – 650 pixels; 700 – 750 pixels and so on.’
なぜかフルHD(2K)の画像だとOKで、HD画像だとNGということもあって、かなり謎です。どっちの画像も750ピクセル超えてるのに、なんで違う結果になるの……というところがあり、個人的には実用的ではないと感じたため扱いませんでした。
Nugetでインストールが終わったら、traineddataという学習データをダウンロードしておきましょう。各言語ごとに用意されていますが、今回は日本語(JPN)をダウンロードしてきます(30MBくらいあります)
環境さえ構築できれば、コーディングは直感的で分かりやすくなってます。画像を指定したら文字列が返ってくる、って感じです。画像の範囲を指定すれば認識率が上がるので、基本的には範囲指定した方がいいでしょう。
// 画像のフルパス using (var image = new System.Drawing.Bitmap(@"C:\image.jpg")) { // jpn.traineddataの格納フォルダ using (var engine = new Tesseract.TesseractEngine(@"C:\tessdata\", "JPN")) // 処理領域の指定なし using (var page = engine.Process(image)) { var ocrText = page.GetText(); } // 処理領域の指定あり // √Letterのように画面下部のメッセージエリアだけを指定したい場合 // x, y, width, height var rect = new Tesseract.Rect(0, 770, 1920, 310); using (var page = engine.Process(image, rect)) { var ocrText = page.GetText(); } }
実行例
画像から文字列を取り出すツールを作ってみたけど、OCRはDLLなので精度は画像によるとしか言いようがない感じ。ゲームによってはかなり認識できるけど、ダメなゲームは全然ダメですね。 pic.twitter.com/qsk6shcBme
— 嶽花 征樹 (@takehana_masaki) 2017年12月12日
文字列部分に少しでもノイズがはいってると途端に認識率が下がるようで、画像によっては全然ダメな場合が多いですね。画面が常にザラザラしてる『Tear ―終わりとはじまりの雫―』はやる前から分かってましたが、ほぼ全滅。
具体的にいうと、Tearはザラザラが最狂すぎて、セリフ部分は一箇所も取得できない。文字の部分の少しでもノイズはいると、認識率がかなり下がるっぽいので、アドベンチャーみたいに下部にガンマ比率がいい塩梅で文字列があれば、けっこう認識できると思う。ルートレターとか。 pic.twitter.com/L6zNS7nq8g
— 嶽花 征樹 (@takehana_masaki) 2017年12月12日
当初はダメだった画像でも、文字のあたりを範囲指定すると途端に認識率が高くなることも多かったので、何パターンか試して一番認識率が高い範囲でOCRするのが良さそうです。
OCRツール、ネットハイは全然読み込めないと思ってたけど、範囲指定したらけっこう読み込めるようになったので、範囲指定の機能つけて正解だった。まぁ画像によってはダメだけど、アドベンチャーゲームのテキストエリアはかなり有効っぽい(Tear以外は) pic.twitter.com/kVyIdwsiIr
— 嶽花 征樹 (@takehana_masaki) 2017年12月13日
OCRツール、ルートレターも範囲指定すれば結構認識してくれたけど、マックスモードだけは全然ダメだった。マックスには勝てなかったよ…… pic.twitter.com/D237T2qdzE
— 嶽花 征樹 (@takehana_masaki) 2017年12月13日
かなり認識率が高い結果になっても、OCRの結果文字列に改行コードや明らかに日本語ではない文字が混じってたりするので、前述したコーディングとは別に、日本語や数字など必要な文字でなければ除外するようなメソッドを用意しました。
2017/12/14追記
どう足掻いてもムリと思ってたTearのザラザラですが、プレビュー画像上でドラッグして範囲指定する機能を追加して、文字のところだけピッタリ指定してみたところ、うまくいきました!
OCRツール、プレビュー領域をドラッグして範囲指定できる機能を追加してみたところ、Tearでも文字読取が割とできるようになったー! C#は最近業務で使い始めたのでLINQとか全然知らなかったんだけど、LINQ to XMLとかかなり便利。知ってれば楽に実装できる機能が多くて、調べがいがあるね。 pic.twitter.com/joITnFCLDn
— 嶽花 征樹 (@takehana_masaki) 2017年12月14日
とりあえず思いついた機能は全て入れてみたので、あとは細かいところをブラッシュアップしてく感じですかね。楽するための苦労は惜しまない。
実行用ファイル
実験的に配布してみます(Windows7、Windows10で動作確認済)。
このソフトを使用して何か障害が起きたとしても、こちらとしては一切責任を負いません。あくまで自己責任で使っていただける場合のみ、ダウンロードしてお使いください。
ImageOcrRename.zip
tessdataフォルダに、jpn.traineddataとeng.traineddataを格納すれば動くはずです(30MB以上あるので、zipファイルにはいれてません)。
直感的に分かるだろうと思うので、詳しい使い方は書きません。というか書いたところで、Nore139さん以外に使う人が居ない気もするので……
バグがあってもよほどのものじゃない限りは改修しないと思います。PGソースが欲しい場合は、フォームなどで連絡いただければ考慮するかもしれません。
コメント